

I'm sorry HighSpace, I love you, I really do, but something about this project has been calling my name.
{kind=link}
It all started with an idea for a decentralized recommendation engine in the vein of stumbleupon.com (I posted about it, but I think it got sucked into the vacuum of that database stroke we suffered a while back), but it has since took on a life of it's own. Originally the idea was to collect all the content I'd normally click “like” on, across various platforms, and present it as a curated feed of cool stuff I saw. The decentralization would come later on, as other people would hopefully join in, and we'd aggregate the results, and present them to each user according to their preferences. I wasn't convinced it's that great of an idea, so it languished for a while, until I remembered an old setup I had with Miniflux and Nitter that I'd use for keeping up with some people I followed, without opening a Twitter account. I thought Miniflux would provide a nice scaffolding for what I wanted to make, and Nitter would be a good start for a source of recommended content.
Nitter's dead, long live Nitter!
As we've all heard Nitter is dead, or is it? At one point I saw someone here link to privacydev's instance and after the core Nitter team gave up, I was using it every once in a while. It sure got slow, and it sure got unreliable, but not unreliable enough for me to believe the core functionality is completely crippled. I suspected it's a question of them not having enough accounts to make all the requests to Twitter, to serve all the people using the instance. Lo and behold, turns out I'm right, even though guest accounts are gone, you can still use it with a regular account, and there's even a script for fetching the auth tokens necessary to make nitter run. So I set the whole thing up, at first mostly just to have a Twitter frontend that's not absolute garbage, and it works like a charm! It's probably a good idea to add a few more accounts to avoid rate-limiting, but I've been using it on a single login without really running into issues.
Nitter's fine and well, but one of it's annoying limitations is that you have to look up an account directly. Timeline support is on it's roadmap, but they never got around to it, and it looks like now they never will. But what they do have is an RSS view, so you can add all the accounts you're interested in, and put their tweets together into a single timeline. For this, as already mentioned, I've used Miniflux. This has a lot of advantages that I really like. First, the tweets are in chronological order, and you can use an “unread” feed to only check the stuff you haven't seen yet. I find it much better than Twitter's “slotmachine” feed that shuffles tweets, lies to you about new content being available, and promotes people you haven't even followed. Secondly the tweets are automatically archived. Some people delete their spiciest takes, and even on Elon's Twitter accounts get occasionally yeeted, but since you're storing the content locally, all their bangers are safe with you. Thirdly - searchability. Twitter's search isn't even that bad, but what's missing for me is the ability to search the stuff I followed or liked. My memory is decent, but vague - “I saw that in a tweet I liked around X time”, “someone I followed used a phrase Y”, etc. Limiting the search to only people I follow, or to bookmarked RSS entries helps a lot.
I also had some issues with the setup. Miniflux only renders the titles of tweets, not their content. On the other hand, for some reason, Nitter renders the whole Tweet in the RSS entry title, which you'd think is a solution to the previous problem, but if you add a feed from non-nitter source, you end up with inconsistent rendering - you can read the tweets without clicking on each entry, but you have to check every entry from other feed types manually. So I made some adjustments! Nitter only renders basic info in the title (tweet author, who they're replying to / retweeting) and Miniflux actually renders the entire content on it's feed pages. The commit also includes the script to get the auth tokens. You can now happily scroll through all your content.
{kind=link}
But wait, there's more!
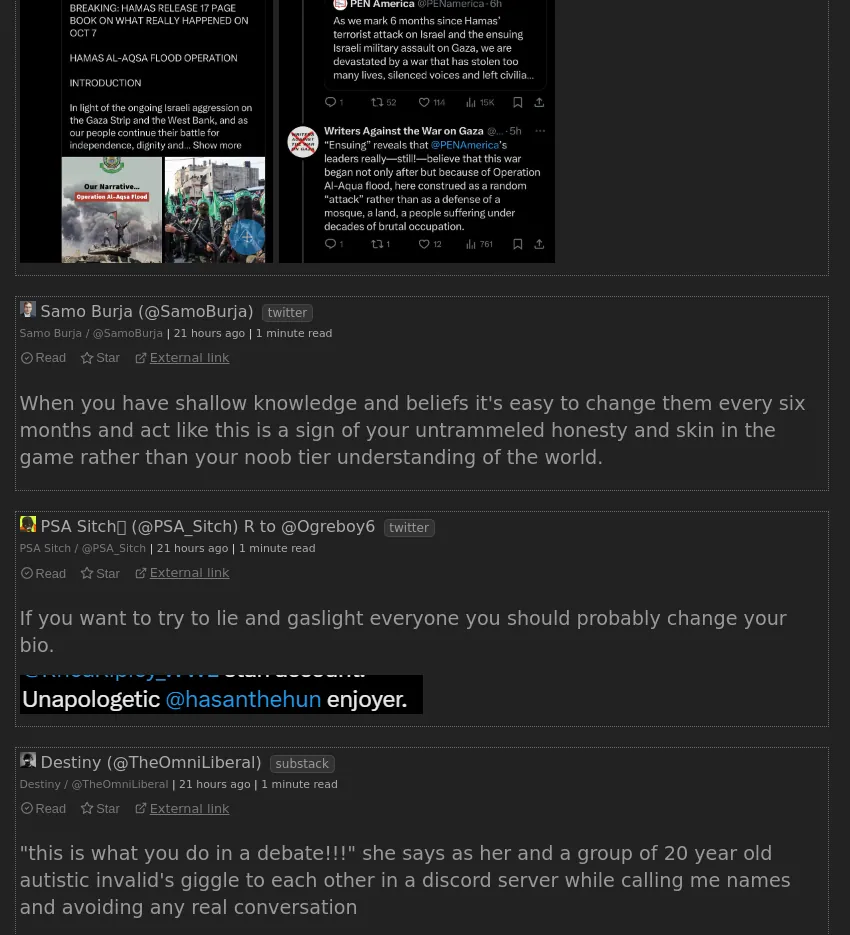
So as I was happily using this setup, it occurred to me that images are quite important in the Twitter ecosystem. Sometimes people post memes with very little comment, sometimes they post screenshots of articles, sometimes they post images of text to get around the character limit. That's not an issue, it all renders fine, but since archiving is an important feature for me, I thought I need to do something about the images in case of banger deletion / account yeeting. So I made further adjustments! When the RSS entries are downloaded, their content is scraped for image tags, and they're automatically saved to Miniflux' database.
But that's not all! Since search is also an important feature for me, I thought “what if someone posts one of those wall-of-text images containing something interesting, and I'll only remember a phrase in the image, but nothing about the text of the tweet or it's author?”. Don't fret, another adjustment I made was to use gosseract, a Golang (which Miniflux is written in) OCR package, to automatically scan and transcribe the images, and to extend the search feature to look up the transcriptions as well! No spicy screenshotted headline will be able to hide from you now!
We're quite far from the original “p2p recommendation engine” idea, but I'm quite happy with the result. Back during one of the dotcom booms there was a saying to the effect of “just make an app you'd want to use”, and by that criterion I feel like I struck gold, so I thought I'd share it. There's potential to develop it further, both Substack and Youtube (still) offer RSS views of their content, and both have relatively-easy-to-access transcriptions. Automatically downloading audio or video content might be a tall order storage-wise, but it definitely will help with my chronic “I know I heard this on one of the several 5-hour long podcasts I listen to daily, but don't know which one" problem.
Now, if you're thinking, "that all sounds nice in theory, but I fell asleep reading the README of the repositories you linked to, and there's now way I'll bother setting any of this up" - you're in luck! For my next performance, if anyone's interested, I might set up a demo server.
If you want to take a stab at setting it up for yourself, and need help, I'll be happy to assist.
Jump in the discussion.
No email address required.
Notes -
If you can get something with around 1GB of RAM for free, it should pan out. If you can only get half of that, it might work, but I feel like you'd be pushing your luck. Although for personal use, the performance hit of using swap shouldn't be too annoying.
More options
Context Copy link